
概要
過去2回、dsPIC33AKシリーズについて紹介しました。
今回は大幅に強化されたCPUの性能についてdsPIC33CHと比較・検証します。
| 記事 | リンク | |
| 第1回 | dsPIC33AKシリーズについて | dsPIC33Aシリーズに関して – ぴくおの電子工作的な何かWP (electricpico.com) |
| 第2回 | 開発ボード、コンフィグレーション設定、クロック設定について | dsPIC33AKシリーズ②開発ボード,コンフィグレーション設定,クロック設定について – ぴくおの電子工作的な何かWP (electricpico.com) |
| 第3回(本記事) | CPU性能について | dsPIC33AKシリーズ③CPU性能について – ぴくおの電子工作的な何かWP (electricpico.com) |
| 第4回(予定) | FPU性能について | |
| 第5回(予定) | DSP性能について |
開発環境
開発環境を以下に示します。
| 項目 | 値 | リンク |
| ベースボード | dsPIC33A CURIOSITY PLATFORM DEVELOPMENT BOARD | dsPIC33A Curiosity Platform Development Board User’s Guide (microchip.com) |
| CPUボード | EV68M17A – dsPIC33AK128MC106 Motor Control DIM | dsPIC33AK128MC106 Motor Control Dual In-Line Module (DIM) Information Sheet (microchip.com) |
| 統合開発環境 | MPLAB X IDE v6.20 | MPLAB® X IDE | Microchip Technology |
| コンパイラ | MPLAB XC DSC v3.10 | MPLAB® XC DSC Compiler | Microchip Technology |

| 項目 | 値 | リンク |
| ベースボード | dsPIC33CH CURIOSITY DEVELOPMENT BOARD | DSPIC33CH CURIOSITY DEVELOPMENT BOARD | Microchip Technology |
| 統合開発環境 | MPLAB X IDE v6.20 | MPLAB® X IDE | Microchip Technology |
| コンパイラ | MPLAB XC DSC v3.10 | MPLAB® XC DSC Compiler | Microchip Technology |
今回の実験のコンフィクレーションおよびクロックの設定は第2回の記事の通りとします。
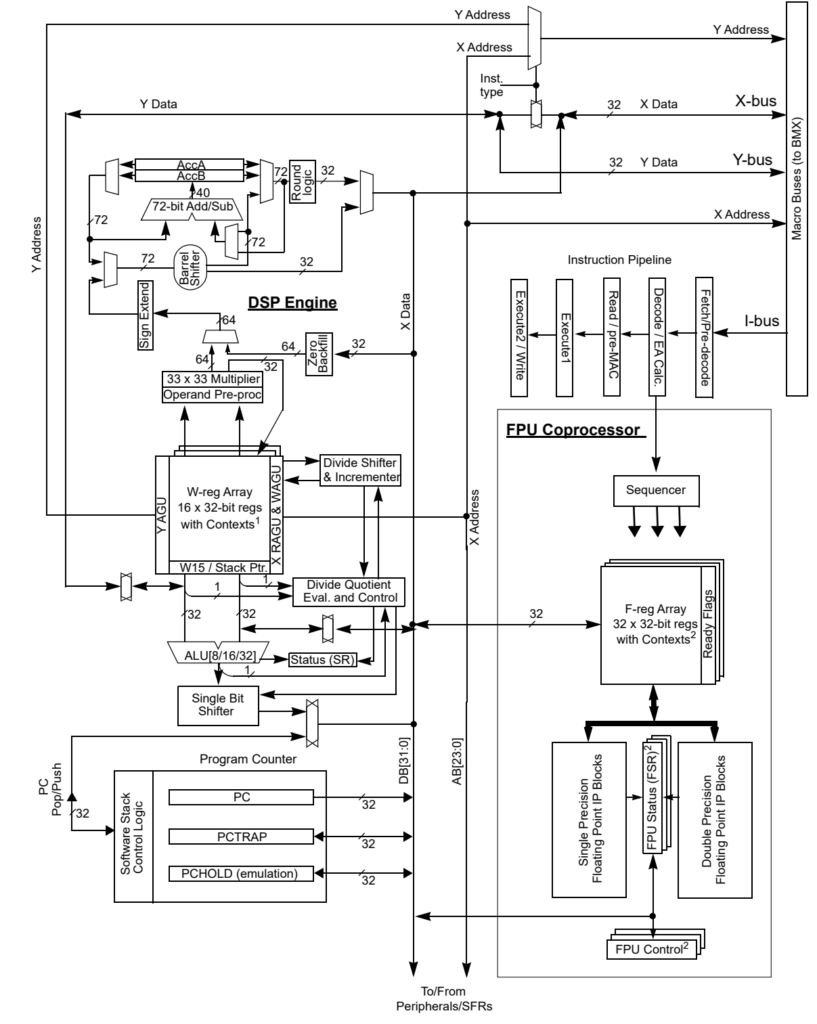
CPU概要
dspPIC33AKシリーズは、システムクロックスピードの向上(100MHz→200MHz)、バス幅拡大(16bit→32bit)、5段インターロック命令パイプライン(*1)、投機実行(*2)、条件分岐レイテンシを提言するプリフェッチ分岐予測を特徴とするCPUアーキテクチャを備えています。また2kBの命令キャッシュによるアクセス時間短縮。発振周波数=命令サイクル数(※注:dsPIC33CKでは発振周波数/2=命令サイクル)、アキュムレータ幅拡大(40bit→72bit)と演算処理性能がdsPIC33Cシリーズと比較し格段に向上しております。
パイプライン構造は、コンピュータのCPUにおいて命令の処理を効率化するための技術です。パイプラインは、命令の実行を複数の段階に分け、各段階を並列に処理することで、CPUの処理能力を向上させます。これにより、1つの命令が完了するまで待たずに次の命令の処理を開始することができます。
パイプライン構造の基本的な段階は以下のようになります:
- フェッチ(Fetch):メモリから命令を読み込む。
- デコード(Decode):読み込んだ命令を解釈し、実行するための準備をする。
- 実行(Execute):命令を実行する。
- メモリアクセス(Memory Access):必要な場合はメモリにアクセスする。
- 書き戻し(Write Back):演算結果をレジスタやメモリに書き戻す。
例えば、以下のように複数の命令を並列で処理することができます:
- 命令1がフェッチ段階にあるとき、
- 命令2はデコード段階に、
- 命令3は実行段階に、
- 命令4はメモリアクセス段階に、
- 命令5は書き戻し段階にある。
このように、パイプラインは各命令が異なる段階にある状態を維持し、常にCPUがフル稼働するように設計されています。
しかし、パイプラインにはいくつかの課題もあります。例えば、条件分岐が発生した場合、どの命令が次に実行されるかが分からなくなり、パイプラインが停止することがあります(パイプラインハザード)。これを解決するために、投機実行や分岐予測などの技術が使用されます。
また、パイプラインの段階が増えると、1つの命令が完了するまでの時間は長くなりますが、並列処理によって全体の処理速度は向上します。このバランスを取ることが、パイプライン設計の重要なポイントです。
CPUの投機実行(Speculative Execution)とは、プロセッサが命令を事前に実行し、実行結果を待たずに次の命令の実行を開始する技術です。この方法は、プログラムの実行を高速化するために使われます。
具体的には、CPUがプログラムの命令を逐次実行する際に、分岐(条件分岐やループなど)があると次に実行する命令が分からない場合があります。その際、CPUは以下のように動作します:
- 予測:CPUはどちらの分岐が選ばれるかを予測します。
- 投機的実行:予測した分岐の命令を事前に実行します。
- 確認:実際の分岐の結果が判明した時点で、予測が正しかった場合はそのまま実行結果を採用し、間違っていた場合は投機的に実行した命令を破棄して正しい分岐の命令を再実行します。
CPUのブロック図を下記に示します。従来のdsPIC33Cシリーズとは大きく構造が異なることが判ります。
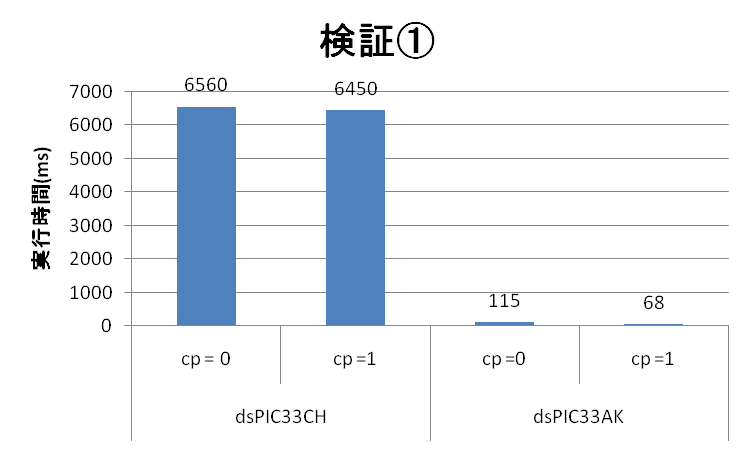
CPU実行速度検証①
100万回ループを繰り返し、ループカウンタが3の倍数で有る時にLED4をセットします。
ソースコード
#define LOOP_COUNT 1000000
int main(int argc, char** argv)
{
int i; //CH はlong i
/*----------------------------------------------------------------------------*/
/* 初期化 */
/*----------------------------------------------------------------------------*/
vdg_Clock_Set_Register();
TRISBbits.TRISB10 = 1u;
TRISDbits.TRISD9 = 0u;
TRISDbits.TRISD10 = 0u;
/*----------------------------------------------------------------------------*/
/* メインルーチン */
/*----------------------------------------------------------------------------*/
while(1)
{
LATDbits.LATD9 ++;
for (i = 0; i < LOOP_COUNT; i++)
{
if ((i % 3)== 0)
{
LATDbits.LATD10 = 1;
}
else
{
LATDbits.LATD10 = 0;
}
}
}
return (EXIT_SUCCESS);
}結果
| 検証①結果 | dsPIC33CH (90MHz Main Core) | dsPIC33AK |
| 実行スピード(ms) (コンパイラオプション = 0) | 6560 | 115 |
| 実行スピード(ms) (コンパイラオプション = 1) | 6450 | 68 |
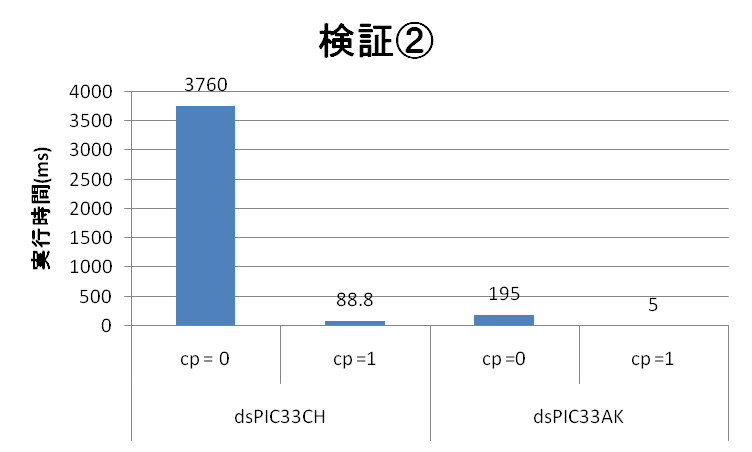
CPU実行速度検証②
条件分岐を使用して投機実行を誘発し、その結果を測定します。
ソースコード
#define LOOP_COUNT 1000000
#define ARRAY_SIZE 100
uint8_t array[ARRAY_SIZE];
uint8_t secret = 42;
void initialize_array()
{
for (int i = 0; i < ARRAY_SIZE; i++) {
array[i] = 0;
}
}
uint8_t access_array(uint8_t index)
{
if (index < ARRAY_SIZE) {
return array[index];
}
return 0;
}
int main(int argc, char** argv)
{
int i;
/*----------------------------------------------------------------------------*/
/*初期化*/
/*----------------------------------------------------------------------------*/
vdg_Clock_Set_Register();
TRISDbits.TRISD9 = 0u;
initialize_array();
/*----------------------------------------------------------------------------*/
/*メインルーチン*/
/*----------------------------------------------------------------------------*/
while(1)
{
LATDbits.LATD9 ++;
for (i = 0; i < LOOP_COUNT; i++)
{
uint8_t index = (i & 1) ? secret : i % ARRAY_SIZE;
access_array(index);
}
}
return (EXIT_SUCCESS);
}結果
| 検証②結果 | dsPIC33CH (90MHz Main Core) | dsPIC33AK |
| 実行スピード(ms) (コンパイラオプション = 0) | 3760 | 195 |
| 実行スピード(ms) (コンパイラオプション = 1) | 88.8 | 5 |
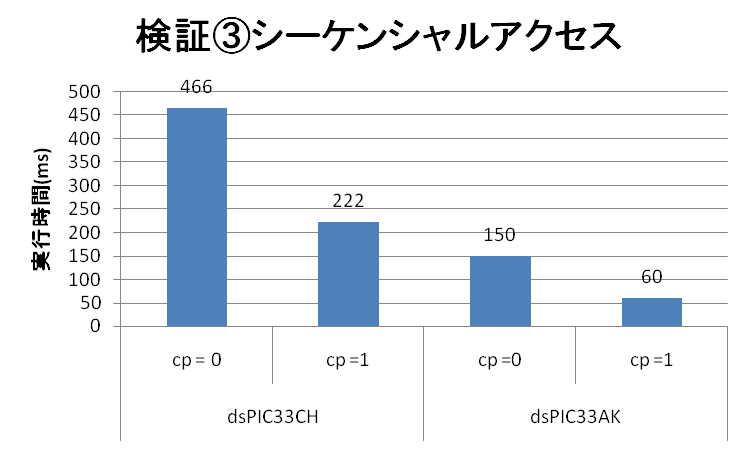
CPU実行速度検証③
連続アクセスとランダムアクセスのパターンを比較し、キャッシュの効果を検証します。
ソースコード
#define ARRAY_SIZE 1024 * 2 //2kB
#define ITERATIONS 1000000
int array[ARRAY_SIZE];
// dsPIC33CHは int を longに置き換え
// 連続アクセス
void sequential_access()
{
for (int i = 0; i < ITERATIONS; i++)
{
array[i % ARRAY_SIZE]++;
}
}
// ランダムアクセス
void random_access()
{
for (int i = 0; i < ITERATIONS; i++)
{
array[rand() % ARRAY_SIZE]++;
}
}
int main()
{
/*----------------------------------------------------------------------------*/
/*初期化*/
/*----------------------------------------------------------------------------*/
vdg_Clock_Set_Register();
TRISDbits.TRISD9 = 0u;
TRISDbits.TRISD10 = 0u;
/*----------------------------------------------------------------------------*/
/*メインルーチン*/
/*----------------------------------------------------------------------------*/
while(1)
{
// 配列の初期化
for (int i = 0; i < ARRAY_SIZE; i++)
{
array[i] = 0;
}
// 連続アクセスの計測
LATDbits.LATD9 = 1u;
sequential_access();
LATDbits.LATD9 = 0u;
LATDbits.LATD10 = 1u;
random_access();
LATDbits.LATD10 = 0u;
}
return (EXIT_SUCCESS);
}結果
| 検証③結果 シーケンシャルアクセス | dsPIC33CH (90MHz Main Core) | dsPIC33AK |
| 実行スピード(ms) (コンパイラオプション = 0) | 466 | 150 |
| 実行スピード(ms) (コンパイラオプション = 1) | 222 | 60 |
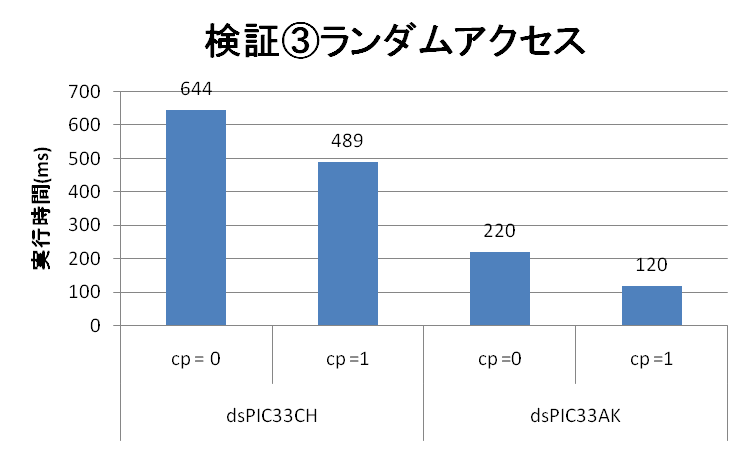
| 検証③結果 ランダムアクセス | dsPIC33CH (90MHz Main Core) | dsPIC33AK |
| 実行スピード(ms) (コンパイラオプション = 0) | 644 | 220 |
| 実行スピード(ms) (コンパイラオプション = 1) | 489 | 120 |
CPU実行速度検証④
ソースコード
#define ARRAY_SIZE 1024 * 2 // 1MBの配列
#define ITERATIONS 1000000
uint8_t array8[ARRAY_SIZE];
uint16_t array16[ARRAY_SIZE / 2];
uint32_t array32[ARRAY_SIZE / 4];
void access_8bit()
{
for (int i = 0; i < ITERATIONS; i++)
{
array8[i % ARRAY_SIZE]++;
}
}
void access_16bit()
{
for (int i = 0; i < ITERATIONS; i++)
{
array16[i % (ARRAY_SIZE / 2)]++;
}
}
void access_32bit()
{
for (int i = 0; i < ITERATIONS; i++)
{
array32[i % (ARRAY_SIZE / 4)]++;
}
}
int main()
{
/*----------------------------------------------------------------------------*/
/*初期化*/
/*----------------------------------------------------------------------------*/
vdg_Clock_Set_Register();
TRISDbits.TRISD9 = 0u;
TRISDbits.TRISD10 = 0u;
TRISCbits.TRISC9 = 0u;
// 配列の初期化
for (int i = 0; i < ARRAY_SIZE; i++)
{
array8[i] = 0;
if (i < ARRAY_SIZE / 2) array16[i] = 0;
if (i < ARRAY_SIZE / 4) array32[i] = 0;
}
/*----------------------------------------------------------------------------*/
/*メインルーチン*/
/*----------------------------------------------------------------------------*/
while(1)
{
// 8ビットアクセスの計測
LATDbits.LATD9 = 1u;
access_8bit();
LATDbits.LATD9 = 0u;
// 16ビットアクセスの計測
LATDbits.LATD10 = 1u;
access_16bit();
LATDbits.LATD10 = 0u;
// 32ビットアクセスの計測
LATCbits.LATC9 = 1u;
access_32bit();
LATCbits.LATC9 = 0u;
}
return 0;
結果
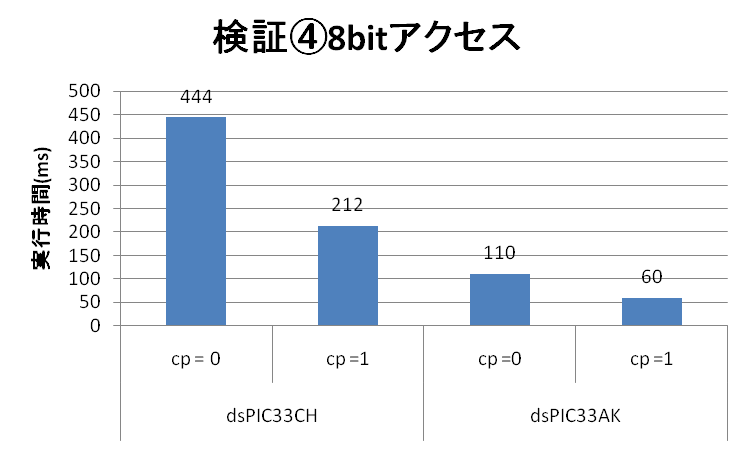
| 検証④結果 8bitアクセス | dsPIC33CH (90MHz Main Core) | dsPIC33AK |
| 実行スピード(ms) (コンパイラオプション = 0) | 444 | 110 |
| 実行スピード(ms) (コンパイラオプション = 1) | 212 | 60 |
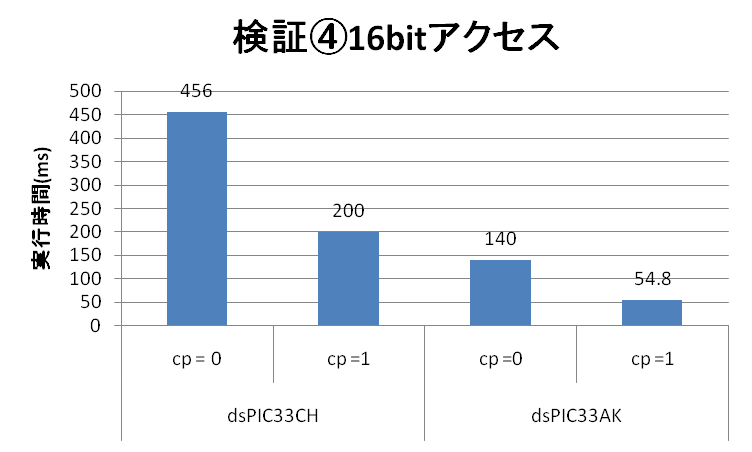
| 検証④結果 16bitアクセス | dsPIC33CH (90MHz Main Core) | dsPIC33AK |
| 実行スピード(ms) (コンパイラオプション = 0) | 456 | 140 |
| 実行スピード(ms) (コンパイラオプション = 1) | 212 | 54.8 |
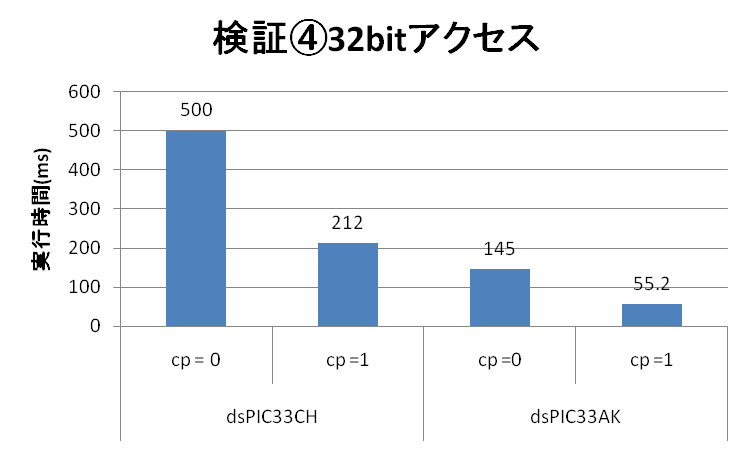
| 検証④結果 32bitアクセス | dsPIC33CH (90MHz Main Core) | dsPIC33AK |
| 実行スピード(ms) (コンパイラオプション = 0) | 500 | 145 |
| 実行スピード(ms) (コンパイラオプション = 1) | 212 | 55.2 |
まとめ
コンパイル結果の詳細は今回は省略しますが、検証③④においては従来の約1/4の実行時間となり、純粋なCPUクロックスピードの違いが影響したと考えられます。 一方、検証①②ではMOD(%)を使用していたため、CPU速度だけでこの差が生じたわけではないかもしれません。
実際には割り込みなども影響するため、もう少し複雑な要因が絡んでいると思いますが、一つの参考値としてご覧いただければ幸いです。
記事についての注意点
本記事は慎重に内容を検討し正確さに努めておりますが、もし内容に誤りがあったとしても、この記事を参考にして生じた損害等については一切の責任を負いません。

コメント